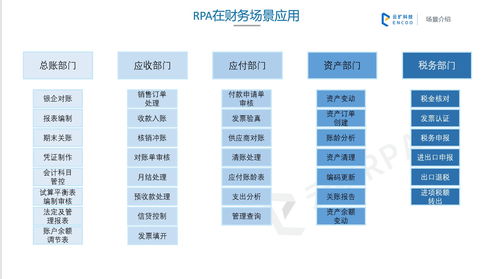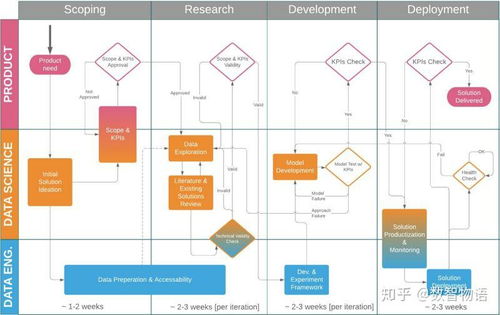
隨著金融行業的數字化發展,數據科學在金融知識流程外包(Knowledge Process Outsourcing, KPO)中的應用日益廣泛。啟動一個成功的數據科學項目需要系統的規劃和執行,尤其是在金融領域,其中涉及的數據敏感性和復雜性較高。本文將介紹如何從零開始啟動一個數據科學項目,專注于金融知識流程外包環境,涵蓋關鍵步驟、工具和最佳實踐。
一、明確項目目標和范圍
在項目啟動前,必須清晰定義業務目標。金融知識流程外包通常涉及風險管理、客戶分析、投資組合優化或合規性檢查等任務。例如,如果目標是通過數據科學改進信用風險評估,需確定具體指標,如減少違約率或提高預測準確度。與利益相關者(如金融專家、外包客戶)溝通,確保項目范圍明確,避免后續范圍蔓延。關鍵問題包括:項目要解決什么金融問題?預期成果是什么?數據來源和可用性如何?
二、數據收集與預處理
數據是數據科學項目的核心。在金融KPO中,數據可能來自內部數據庫、公開市場數據或客戶提供的第三方數據源。識別相關數據,如交易記錄、財務報表或市場指數。接著,進行數據清洗,處理缺失值、異常值和重復數據,以確保數據質量。金融數據常涉及時間序列,需注意時間對齊和標準化。使用工具如Python(Pandas庫)或SQL進行預處理,并確保遵守數據隱私法規(如GDPR或金融行業規范)。
三、構建數據科學團隊和基礎設施
一個有效的團隊是項目成功的關鍵。在金融KPO環境中,團隊應包括數據科學家、金融分析師、領域專家和項目經理。明確角色分工:數據科學家負責模型開發,金融專家提供行業洞察,項目經理協調資源和時間線。同時,建立技術基礎設施,如云平臺(AWS或Azure)用于數據存儲和計算,版本控制工具(Git)管理代碼,并采用敏捷方法進行迭代開發。金融項目往往需要高安全性和合規性,因此需部署加密和訪問控制機制。
四、模型開發與驗證
基于預處理的數據,開始構建和訓練模型。根據項目目標,選擇合適算法,例如回歸模型用于預測股價,分類模型用于欺詐檢測,或聚類分析用于客戶細分。在金融領域,模型需具備可解釋性和穩健性,避免黑箱問題。使用交叉驗證和回測技術評估模型性能,確保在歷史數據上表現良好。驗證過程應與金融專家協作,檢查模型是否符合行業邏輯和監管要求。工具如Scikit-learn、TensorFlow或專用金融庫(如QuantLib)可加速開發。
五、部署與監控
模型開發完成后,部署到生產環境中,以供金融KPO客戶使用。這可以是API接口、儀表板或集成到現有系統。部署后,持續監控模型性能,檢測數據漂移或概念漂移,及時調整模型。金融市場的動態性要求定期更新數據和重新訓練模型。同時,建立反饋機制,收集用戶輸入以改進解決方案。項目收尾時,文檔化整個過程,包括數據流水線、模型參數和業務影響,便于知識轉移和外包協作。
六、總結與最佳實踐
啟動一個數據科學項目在金融KPO中需要跨學科協作和嚴格流程。關鍵成功因素包括:明確目標、高質量數據、團隊協作、持續監控和合規性管理。建議從小型試點項目開始,逐步擴展,以降低風險。通過這種方式,數據科學可以顯著提升金融外包服務的效率和價值,例如通過自動化報告生成或增強決策支持。最終,項目應聚焦于交付可衡量的業務成果,從而鞏固客戶關系和競爭優勢。